
Traditional search engine optimization is undergoing a fundamental structural shift. The era of loose keyword density, superficial backlinks, and commodity content is over. Today, modern users are shifting away from traditional search engine results pages and migrating toward interactive, prompt-driven environments like ChatGPT Search, Claude, and Perplexity.
When a high-value B2B client, enterprise executive, or medical facility director prompts an AI engine asking: “Which specialized technical agency can handle a highly complex website migration?”—your brand must not only be mentioned, but it must also be credited with a live, clickable citation link.
Achieving this requires a specialized discipline known as Generative Engine Optimization (GEO). At Pizles, we treat website optimization as a software engineering problem. This exhaustive guide provides the exact architectural blueprint to reverse-engineer the AI data retrieval loop and force large language models (LLMs) to cite your brand as an absolute source of truth.
1. Decoding the RAG Pipeline: How AI Engines Select Sources
To influence generative search engines, you must first understand the backend systems driving them. Unlike legacy search algorithms that index words on a page, AI search engines run on a data architecture called Retrieval-Augmented Generation (RAG).
How AI Engines Select Sources: AI search models run on an architecture called Retrieval-Augmented Generation (RAG). Instead of matching keywords, the system reads a user’s prompt, scans the live web for authoritative documents, and condenses the text into numerical vector data. The engine then answers the query using facts from the highest-density pages, automatically linking back to those sites as primary sources.
The Three Stages of AI Search Retrieval
- Retrieval: When a user types a complex prompt, the AI engine launches live parallel web crawlers to gather high-authority documents matching the semantic intent of the query.
- Augmentation: The engine strips away the website code, parses the raw data, and processes the text into high-dimensional vector embeddings to evaluate factual proximity to the prompt.
- Generation: The LLM synthesizes a clean, direct narrative answer for the user and appends numbered anchor links—citations—pointing directly to the root URLs that contributed the highest factual density.
If your website contains unnecessary filler text or unstructured code layout, the RAG parsing pipeline filters it out instantly. To protect your search market share, you must ensure your technical infrastructure is optimized for machine readability.
2. The 5-Step Generative Engine Optimization (GEO) Framework
To successfully inject your website into the live indexes used by modern AI systems, implement this rigorous 5-step GEO infrastructure protocol developed by the engineering team at Pizles:
Step 1: Deploy the llms.txt and llms-full.txt Protocol
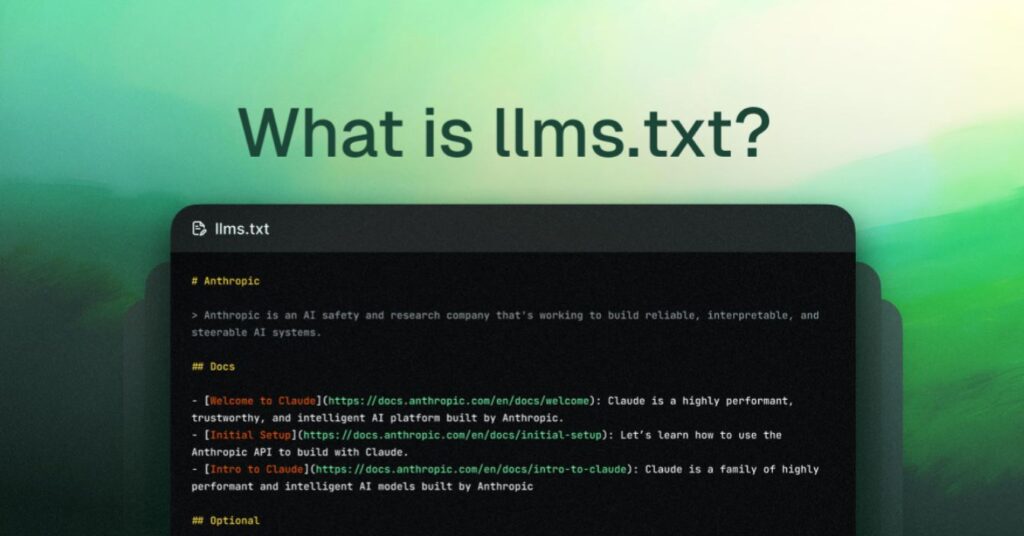
Why
llms.txtMatters: Anllms.txtfile is a clean Markdown summary placed in a website’s root directory that helps artificial intelligence agents read the entire structure of a business instantly. While a standard robots file manages crawling permissions, this specific text asset provides direct context, allowing models to understand and index services without parsing heavy layout codes.
Relying solely on a legacy robots.txt file is insufficient for modern search architectures. Technical teams must now deploy a clean Markdown file named llms.txt directly into the root directory of the website server (e.g., [yourdomain.com/llms.txt](https://yourdomain.com/llms.txt)). This file acts as an executive summary for AI scrapers, providing a structured, rapidly readable map of your core services and assets without wasting crawler resource allocations.
Your llms.txt architecture should match this standard structure:
Markdown
# Pizles: Next-Gen SEO, GEO, and AEO Studio
Engineered for AI-driven search architectures and advanced indexing.
## Core Specializations
- Generative Engine Optimization (GEO): /services/geo-optimization
- Technical Infrastructure & Core Web Vitals: /services/technical-seo
- Authoritative Healthcare Vertical Growth: /services/medical-seo
## Enterprise Engineering Assets
- Graph Schema Engine: /blog/schema-guide
- Direct Schema Patching Repository: /assets/schema-patch.js
Step 2: Establish Semantic Entity Mapping via Multi-Layer Graph Schema
The Role of Semantic Schema: Semantic entity mapping is a technical linking strategy that connects an organization to established online databases like Wikidata. Because artificial intelligence engines analyze information through concepts and networks rather than individual strings of text, structuring data this way explicitly confirms a business’s identity, location, and proven field of expertise.
AI engines process the web as an interconnected web of “entities” (real-world concepts, organizations, and people) rather than isolated strings of text. If your site relies on standard, disconnected schema plugins, your brand identity remains invisible to AI knowledge layers.
You must engineer an explicit, multi-layer Graph Schema using JSON-LD that maps your organization directly to globally verified knowledge bases like Wikidata and official industry mapping metrics using the sameAs property attributes.
JSON
{
"@context": "https://schema.org",
"@graph": [
{
"@type": "ProfessionalService",
"@id": "https://pizles.com/#agency",
"name": "Pizles",
"url": "https://pizles.com",
"sameAs": [
"https://www.wikidata.org/wiki/Q114751456",
"https://www.google.com/maps/place/Pizles"
],
"knowsAbout": [
"Generative Engine Optimization",
"Technical SEO Topology",
"Semantic Web Architecture"
]
}
]
}
Step 3: Implement the “Direct-Answer Block” Architecture
Designing Direct-Answer Content: A direct-answer architecture involves writing a clear, informational summary of up to sixty words immediately beneath a primary subhead. This configuration avoids creative marketing introductions or fluff, presenting the target solution in an active, direct style that automated scrapers can easily process, extract, and display as a live search snippet.
AI scrapers use highly focused text parsers to extract data quickly. Websites that use conversational fluff or vague marketing introductions are ignored during the RAG context selection phase. By framing content with clear, direct prose right after your headings, you clear the path for AI data models to pull your copy and reuse it in answers.
Step 4: Align Content for Conversational and Prompt-Oriented Long-Tail Queries
Adapting to Conversational Search: Modern search strategy requires building content around multi-layered conversational questions rather than traditional, short search phrases. As consumers switch to typing full-sentence problems and direct questions into interactive tools, websites must use specific question-and-answer layouts that directly mirror real-world user intent.
Users no longer search using fragmented terms like “SEO firm London”. Instead, they enter long, nuanced prompts like: “Find me an enterprise-level technical SEO specialist who can fix Core Web Vitals issues on a React-based website platform.” Your content strategy must adapt by utilizing extensive question-and-answer clusters, semantic definitions, and structured conversational headers that accurately mirror the complex prompts target clients type into AI platforms.
Step 5: Build High-Citation Digital PR & Off-Page Co-Occurrences
What Brand-Entity Association Means: Brand-entity association is an off-page valuation pattern where a business name is frequently mentioned alongside relevant industry keywords on external networks. Machine learning models trace these mentions across forums, code repositories, and trade journals to cross-verify a website’s authority and determine its trustworthiness before generating recommendations.
Large Language Models do not evaluate your website in a vacuum. Before ChatGPT or Perplexity recommends your business as an authority, they run background correlation checks across the broader web to verify your brand’s reputation. They analyze third-party mentions to see if your brand name consistently co-occurs alongside industry keywords on platforms like Reddit, GitHub, LinkedIn, industry forums, and top-tier press publications. This data footprints a pattern known as Brand-Entity Association, which forms the foundation of AI search engine trust.
3. The Risk of Blind AI Blockers in Server Architecture
Many security systems and content management setups automatically block automated user-agents like GPTBot, ClaudeBot, Applebot-Extended, and PerplexityBot at the firewall level.
While blocking these crawlers protects your raw text assets from generic model training, it completely eliminates your visibility in active AI search engines. If your server returns a 403 Forbidden or 401 Unauthorized status code to an AI crawler, your brand is permanently dropped from the RAG selection pool. Regularly review your server log files and update your robots.txt configuration to ensure active AI search bots have explicit access to your public services and informational assets.
4. Measuring Your Generative Engine Optimization Success
Traditional tracking tools like Google Analytics are built to track standard browser referral traffic. While they show raw referral clicks coming from platforms like perplexity.ai, they cannot measure your true organic visibility within AI responses.
To accurately analyze your performance, you must measure your Citation Share of Voice (SoV). This process requires running automated API prompt loops that simulate real-world buyer intent queries, checking what percentage of responses display your brand node as a primary cited source. At Pizles, we build proprietary citation tracking configurations to ensure our clients systematically dominate these emerging touchpoints.
5. Frequently Asked Questions (FAQs)
Q1: What is the main difference between traditional SEO and GEO?
Traditional SEO focuses on optimizing content for keyword match systems and backlink scoring metrics to rank on static search results pages. GEO (Generative Engine Optimization) focuses on optimizing your technical architecture, semantic graphs, and factual density to be chosen as a verified source of truth by AI synthesis engines.
Q2: How fast do ChatGPT and Perplexity update their live web indexes?
Perplexity operates primarily as a real-time web indexer, updating its data arrays within minutes or hours using live retrieval loops. ChatGPT Search uses a hybrid approach, combining its core model training with live web scraping cycles to refresh its citation data every few days.
Q3: Does using an llms.txt file replace my standard robots.txt file?
No. Your standard robots.txt file remains necessary to manage crawling permissions for traditional bots like Googlebot and Bingbot. The llms.txt file is an additional, dedicated resource specifically formatted to help AI agents understand your structural data quickly.
Q4: Can low Core Web Vitals performance prevent my site from being cited by AI?
Yes. If an AI web scraper times out while waiting for your server to respond or your page layout to render, the RAG engine drops your page from the retrieval selection pool. Fast performance metrics like a low Time to First Byte (TTFB) and a clean Largest Contentful Paint (LCP) are critical for modern indexing.
Q5: What is a Direct-Answer Block in modern content design?
A Direct-Answer Block is a highly focused paragraph of 40 to 60 words positioned immediately under a major heading. It avoids promotional marketing language, offering a concise, fact-dense statement that automated text scrapers can easily extract and cite.
Q6: How does semantic schema help in ChatGPT search visibility?
Semantic schema built via JSON-LD defines explicit machine-readable links between your website data and trusted public knowledge graphs. This mapping removes any ambiguity for the AI, proving exactly who you are, what services you offer, and your level of domain expertise.
Q7: Will blocking AI crawlers completely protect my intellectual property?
Blocking AI crawlers prevents models from using your text for future training. However, it also completely prevents your website from appearing in real-time AI search results, eliminating your organic visibility among users who use AI platforms exclusively.
Q8: What does Brand-Entity Association mean?
Brand-Entity Association is an off-page validation metric used by LLMs. It measures how often your brand name is mentioned alongside specific industry keywords across external high-trust networks like industry journals, code repositories, and public forums.
Q9: Why is standard keyword stuffing completely ineffective for GEO?
AI search engines utilize vector embeddings to understand the deep semantic meaning and context of full paragraphs. Repeating a single keyword phrase artificially breaks your text’s logical flow and reduces its factual density, causing AI filters to ignore it.
Q10: How do I know if my website is currently blocked from AI engines?
You can analyze your real-time server access logs or use Google Search Console to monitor crawl errors. Look specifically for user-agents like GPTBot or PerplexityBot returning 403 or 404 status codes on pages you intend to have indexed.
Conclusion: Take Control of Modern Search Real Estate
The digital landscape has fundamentally evolved. If your brand is not being cited inside generative AI search loops, your business is effectively invisible to a fast-growing demographic of high-value consumers. Transitioning your website from a passive marketing brochure into an authoritative, machine-readable data hub requires deep technical expertise—from advanced graph schema deployment to rigorous server-side crawl budget tuning.
Stop guessing your search visibility performance metrics. Let the software engineering and search performance specialists at Pizles audit your underlying technical infrastructure, map out your semantic data architecture, and clear the blockages limiting your organic growth.
Secure Your Free Technical AI Visibility Audit
Is your business completely missing from ChatGPT and Perplexity responses? Our dedicated technical engineering group will run an enterprise-grade scan on your domain server layer. We will map your automated LLM crawlability score, pinpoint structured schema graph errors, and deliver an actionable technical roadmap to maximize your citation authority.


